7 formas de eliminar duplicados de un array en Javascript
Aquí está el array del que queremos eliminar los duplicados:

Set
Este es mi método favorito para el desarrollo diario porque es el más fácil de usar entre todos los métodos de eliminación de duplicados. Set es un nuevo tipo introducido por ES6, y la diferencia con Array es que los datos en el tipo Set no pueden tener valores duplicados. Por supuesto, hay algunos métodos de Array que Set no puede llamar.
function unique(arr) {
return Array.from(new Set(arr));
}
Primero usa new Set() para convertir el array original en datos de tipo Set, y luego convierte los datos de tipo Set en un nuevo array que ha sido filtrado para eliminar duplicados. Cuando hablamos de Set a Array, podemos usar Array.from() o podemos usar la forma estructural [... .new Set(arr)].
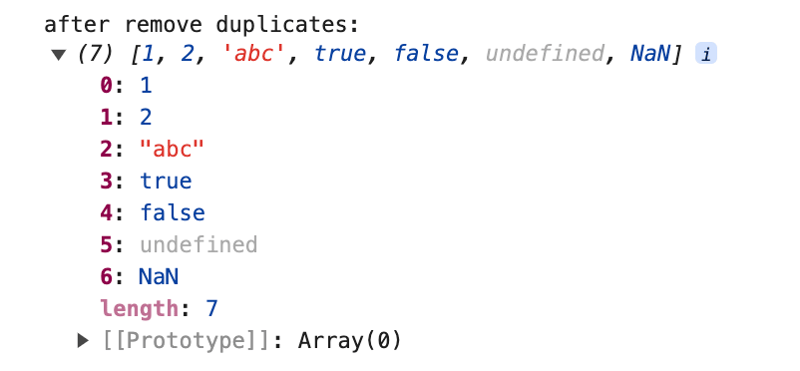
La eliminación de duplicados con Set también funciona para la eliminación de duplicados de NaN y undefined, porque tanto NaN como undefined pueden almacenarse en un Set, y los NaN se tratan como el mismo valor entre sí (aunque en JavaScript: NaN !== NaN).
doble for + splice
Los elementos del array se comparan uno por uno en un bucle for de dos niveles, y los duplicados se eliminan con el método splice.
function unique(arr) {
let len = arr.length;
for (let i = 0; i < len; i++) {
for (let j = i + 1; j < len; j++) {
if (arr[i] === arr[j]) {
arr.splice(j, 1);
len--;
j--;
}
}
}
return arr;
}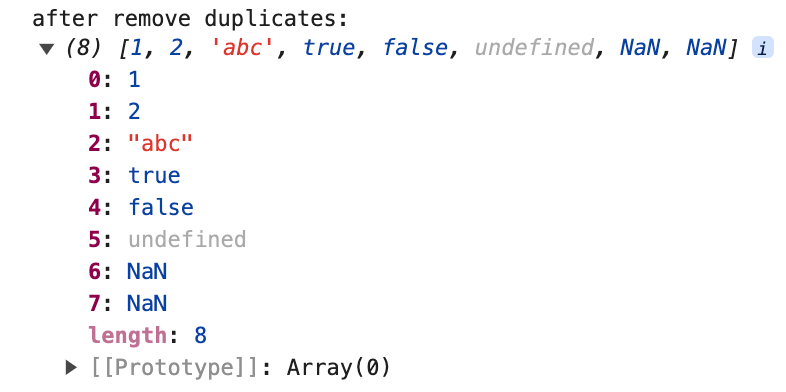
Este método no puede filtrar NaN porque NaN !== NaN al comparar.
indexOf / includes
Crea un nuevo array vacío, recorre el array que necesita ser depurado, inserta los elementos del array en el nuevo array y juzga si el nuevo array ya contiene el elemento actual antes de insertarlo; si no, entonces lo inserta. Este método tampoco puede filtrar NaN. Para juzgar si un array ya contiene el elemento actual, usa el método indexOf o includes.
indexOf
El método indexOf() de las instancias de Array devuelve el primer índice en el que se puede encontrar un elemento dado en el array, o -1 si no está presente.
function unique(arr) {
const newArr = [];
arr.forEach((item) => {
if (newArr.indexOf(item) === -1) {
newArr.push(item);
}
});
return newArr;
}
includes
La lógica de includes es similar a indexOf, podemos usarlo para juzgar si un array contiene un elemento.
El método includes() de las instancias de Array determina si un array incluye un cierto valor entre sus entradas, devolviendo true o false según corresponda.
function unique(arr) {
const newArr = [];
arr.forEach((item) => {
if (!newArr.includes(item)) {
newArr.push(item);
}
});
return newArr;
}
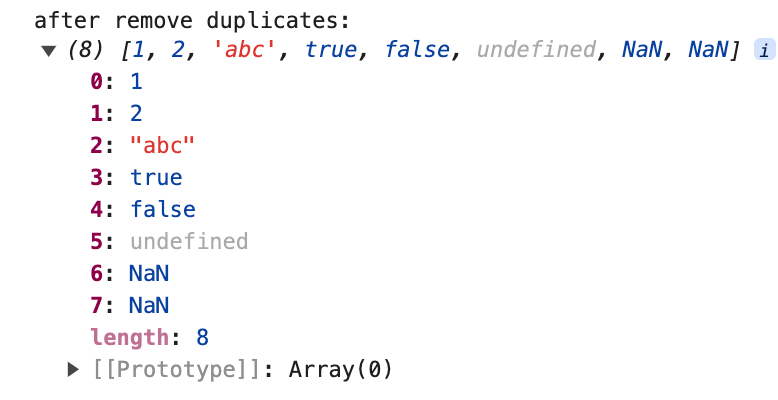
Dado que includes puede encontrar correctamente variables del tipo NaN, puede eliminar datos de tipo NaN.
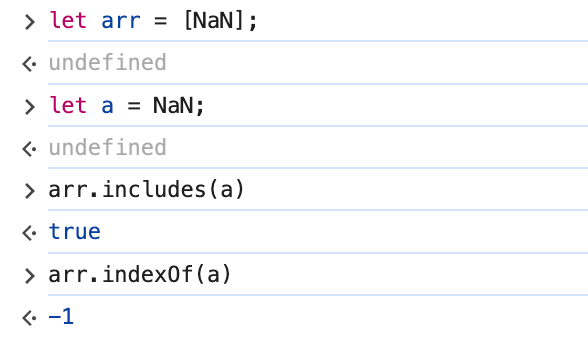
Como podemos ver en el ejemplo, includes(NaN) devuelve true, mientras que indexOf(NaN) devuelve -1.
filter
Podemos usar filter() + indexOf().
El método filter() de las instancias de Array crea una copia superficial de una parte de un array determinado, filtrada hasta los elementos del array que pasan la prueba implementada por la función proporcionada.
La característica de indexOf es devolver el índice de la primera posición contenida en el objetivo a encontrar, podemos filtrar solo el primer elemento de cada dato individual, los duplicados restantes serán filtrados.
function unique(arr) {
return arr.filter((item, index) => {
return arr.indexOf(item) === index;
});
}
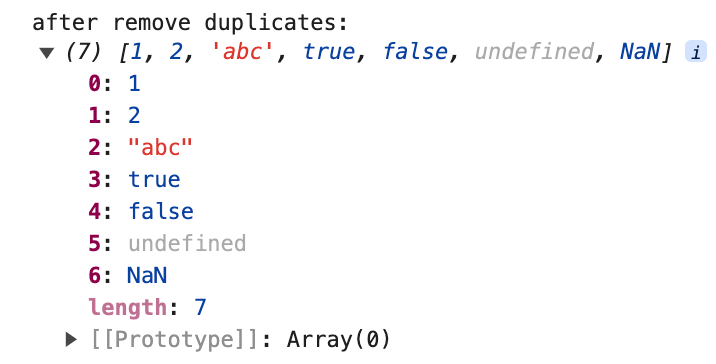
Aquí la salida no contiene NaN, porque indexOf() no puede juzgar NaN, es decir, arr.indexOf(item) === index devuelve false.
Map / Object
Map
El objeto Map es una estructura de datos proporcionada por JavaScript que está estructurada como un par clave-valor y recuerda el orden original de inserción de las claves. Cualquier valor (objeto o valor bruto) puede usarse como una clave o un valor.
function unique(arr) {
const map = new Map();
const newArr = [];
arr.forEach((item) => {
if (!map.has(item)) {
map.set(item, true);
newArr.push(item);
}
});
return newArr;
}
Un elemento del array se almacena como una clave de un map, y luego los métodos has() y set() se combinan para determinar si la clave está duplicada o no.
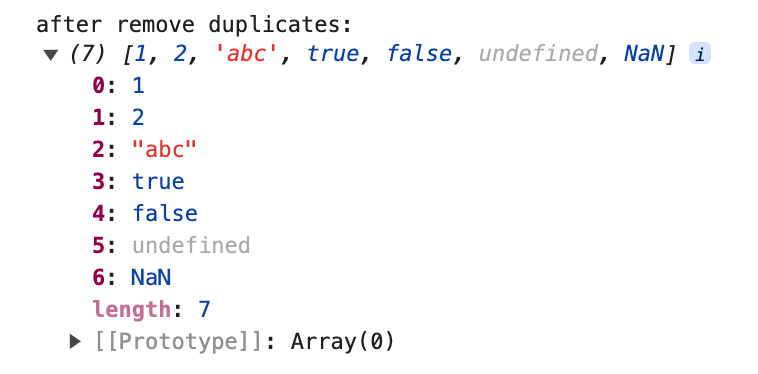
NaN también puede ser eliminado después de usar Map(), porque Map hace un juicio de que NaN es igual a NaN, dejando todos los demás valores para ser juzgados como iguales o no basándose en el resultado del operador ===.
Object
Usar el tipo Object para filtrar es similar a usar Map, este método utiliza principalmente la característica de que el nombre de la propiedad del objeto no puede repetirse.
function unique(arr) {
const newArr = [];
const obj = {};
arr.forEach((item) => {
if (!obj[item]) {
newArr.push(item);
obj[item] = true;
}
});
return newArr;
}
sort
Usa sort() para ordenar, luego recorre y compara elementos vecinos basándote en el resultado ordenado.
function unique(arr) {
arr = arr.sort();
let newArr = [];
for (let i = 0; i < arr.length; i++) {
arr[i] === arr[i - 1] ? newArr : newArr.push(arr[i]);
}
return newArr;
}Si el elemento actual no es igual al anterior, se inserta en el nuevo array.
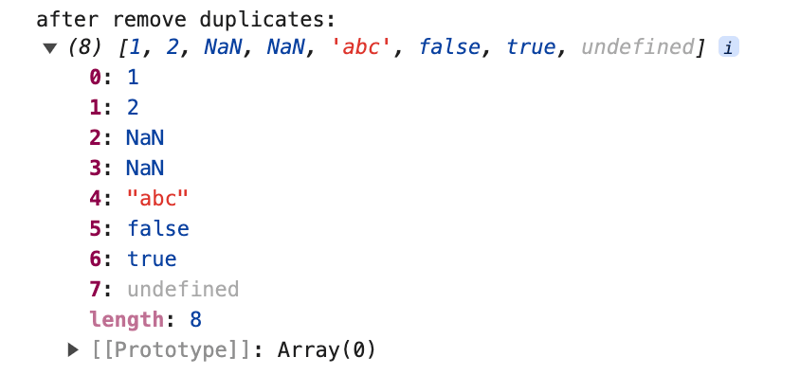
Este método cambia la posición original del array y no puede eliminar datos NaN.
reduce
El reduce() ejecuta una función de devolución de llamada para cada elemento del array por turno, tomando cuatro argumentos: el valor inicial initialValue (o el valor devuelto de la función de devolución de llamada anterior), el valor del elemento actual, el índice actual y el array desde el que se llamó reduce.
function unique(arr) {
return arr.reduce((prev, next) => {
return prev.includes(next) ? prev : [...prev, next];
}, []);
}Al inicializar, definimos un nuevo array, y cada vez que hacemos un bucle, determinamos si los valores del array antiguo ya se han almacenado en el nuevo array, y si no, los añadimos al nuevo array.

Jorge García
Fullstack developer