¿Qué es la técnica de Gradient Boosting en Machine Learning?

- ¿Qué es Gradient Boosting?
- ¿Cómo funciona Gradient Boosting?
- Ejemplo gráfico del proceso
- Ventajas de Gradient Boosting
- Desventajas de Gradient Boosting
- Aplicaciones de Gradient Boosting
- Algoritmos populares de Gradient Boosting
- Conclusión
En el mundo del machine learning, existen diversas técnicas para mejorar la precisión de los modelos predictivos. Una de las más populares y eficaces es el Gradient Boosting. Esta técnica se utiliza principalmente para problemas de clasificación y regresión, y se ha ganado un lugar destacado debido a su capacidad para producir modelos de alta precisión. En este artículo, exploraremos en detalle qué es el Gradient Boosting, cómo funciona y sus principales aplicaciones.
¿Qué es Gradient Boosting?
Gradient Boosting es un método de aprendizaje supervisado que combina múltiples modelos débiles (normalmente árboles de decisión) para formar un modelo fuerte y preciso. A diferencia de otros métodos como bagging (por ejemplo, Random Forest), donde los modelos débiles se entrenan de manera independiente, en Gradient Boosting los modelos se construyen secuencialmente, donde cada nuevo modelo intenta corregir los errores del modelo anterior.
La palabra "boosting" se refiere a la idea de mejorar ("boost") la precisión combinando varios modelos simples (también conocidos como weak learners o modelos débiles). El término "gradient" hace referencia a que el algoritmo utiliza el gradiente descendente para minimizar los errores en cada etapa.
¿Cómo funciona Gradient Boosting?
El funcionamiento del Gradient Boosting puede dividirse en los siguientes pasos:
1. Modelo inicial
El algoritmo comienza con un modelo simple, usualmente un árbol de decisión pequeño (árbol con poca profundidad), que predice el resultado promedio de los datos de entrenamiento. Este primer modelo generalmente no es muy preciso y tiene varios errores.
2. Cálculo de los residuos (errores)
El segundo paso es calcular los residuos, es decir, la diferencia entre las predicciones del modelo y los valores reales. Estos residuos representan el error que el modelo debe corregir.
3. Ajuste del modelo para los residuos
Se entrena un nuevo modelo para predecir los residuos del modelo anterior. En lugar de predecir el resultado directamente, este modelo se enfoca en predecir los errores cometidos por el modelo anterior.
4. Actualización del modelo
Una vez que el nuevo modelo predice los errores, las predicciones anteriores se ajustan sumando las predicciones del nuevo modelo, ponderadas por un factor de aprendizaje (learning rate). El factor de aprendizaje controla la contribución de cada nuevo modelo a la predicción final. Un learning rate más pequeño significa que el algoritmo necesita más modelos para converger, pero puede generar mejores resultados.
5. Repetición del proceso
Este ciclo de calcular residuos, entrenar un nuevo modelo para los residuos y ajustar las predicciones continúa durante varias iteraciones. Cada nuevo modelo se agrega secuencialmente para corregir los errores de los modelos anteriores.
6. Predicción final
El resultado final es una combinación de todos los modelos entrenados. Como cada modelo se ha ajustado para corregir los errores del anterior, la precisión del modelo final es considerablemente mayor que la de cualquier modelo individual.
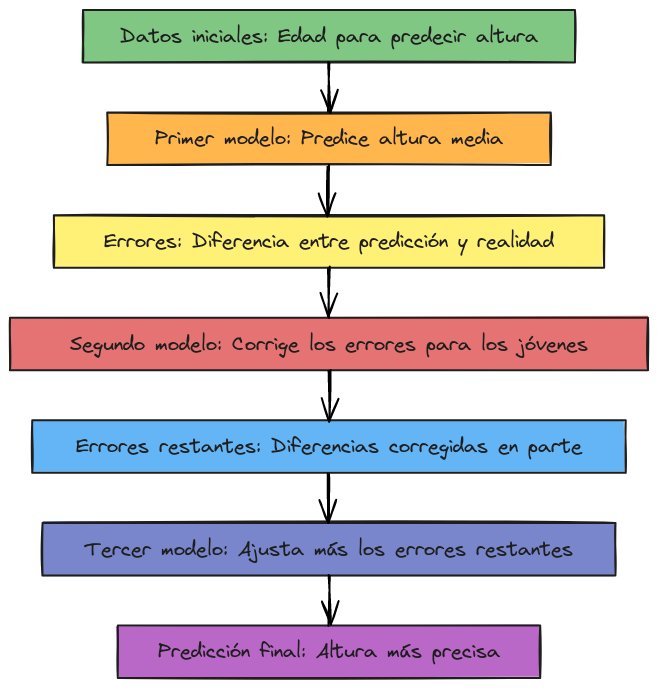
Ejemplo gráfico del proceso
Para ilustrar el funcionamiento de Gradient Boosting, imagina que tienes un conjunto de datos en el que intentas predecir la altura de una persona a partir de su edad. El primer modelo podría predecir que todas las personas tienen una altura media. Luego, el segundo modelo intentará corregir los errores de esta predicción (por ejemplo, diciendo que los jóvenes son más bajos que el promedio). El tercer modelo, a su vez, corregirá los errores del segundo, y así sucesivamente, hasta que el conjunto final de modelos ofrezca una predicción muy precisa.
Ventajas de Gradient Boosting
El éxito del Gradient Boosting en comparación con otros algoritmos de machine learning proviene de varias ventajas clave:
1. Alta precisión: Al corregir continuamente los errores de los modelos anteriores, el Gradient Boosting tiende a ser más preciso que muchos otros algoritmos, especialmente cuando se ajusta correctamente.
2. Flexibilidad: Puede adaptarse a una variedad de tipos de datos y problemas, tanto de clasificación como de regresión.
3. Capacidad de ajuste: El uso de un factor de aprendizaje permite controlar el grado de ajuste del modelo y prevenir el sobreajuste, un problema común en machine learning.
Desventajas de Gradient Boosting
A pesar de sus numerosas ventajas, el Gradient Boosting también presenta algunas desventajas:
1. Tiempo de entrenamiento: El proceso secuencial de entrenamiento de varios modelos puede ser computacionalmente costoso y lento en comparación con otros algoritmos como Random Forest.
2. Sensibilidad a los hiperparámetros: El rendimiento del modelo puede depender en gran medida de la configuración correcta de hiperparámetros como el número de iteraciones, la profundidad de los árboles y el factor de aprendizaje.
3. Sobreajuste: Aunque el algoritmo es potente, también es susceptible a sobreajustarse si no se controla adecuadamente. El sobreajuste ocurre cuando un modelo se ajusta demasiado bien a los datos de entrenamiento, lo que provoca un rendimiento deficiente en datos nuevos o no vistos.
Aplicaciones de Gradient Boosting
El Gradient Boosting se utiliza en una variedad de aplicaciones de machine learning debido a su capacidad para manejar tanto problemas de regresión como de clasificación. Algunas de sus aplicaciones más comunes incluyen:
- Sistemas de recomendación: Muchos sistemas de recomendación (como los utilizados por Netflix o Amazon) utilizan Gradient Boosting para ofrecer recomendaciones precisas a los usuarios.
- Predicción de valores inmobiliarios: En el mercado inmobiliario, se puede utilizar para predecir el valor de una propiedad basándose en características como ubicación, tamaño y características del inmueble.
- Modelos de riesgo crediticio: Las instituciones financieras utilizan Gradient Boosting para predecir el riesgo crediticio de sus clientes.
- Detección de fraudes: En la detección de fraudes, es común utilizar este algoritmo para identificar patrones inusuales en los datos transaccionales que podrían indicar fraudes.
Algoritmos populares de Gradient Boosting
Existen varias implementaciones populares del algoritmo de Gradient Boosting:
1. XGBoost: Es una de las implementaciones más conocidas y optimizadas de Gradient Boosting. Es altamente eficiente y ofrece varias mejoras sobre el algoritmo básico.
2. LightGBM: Esta versión está diseñada para ser más rápida y eficiente en memoria, lo que la hace adecuada para grandes conjuntos de datos.
3. CatBoost: Desarrollado por Yandex, es especialmente eficaz para trabajar con datos categóricos sin necesidad de realizar muchas transformaciones previas.
Conclusión
El Gradient Boosting es una técnica poderosa y flexible para mejorar la precisión de los modelos de machine learning. Si bien puede requerir un tiempo considerable para entrenar y ajustar correctamente, los resultados obtenidos suelen justificar el esfuerzo, especialmente en aplicaciones críticas donde la precisión es crucial.
Gracias a implementaciones avanzadas como XGBoost, LightGBM y CatBoost, el Gradient Boosting sigue siendo una herramienta esencial en el conjunto de herramientas de cualquier científico de datos o ingeniero de machine learning.

Jorge García
Fullstack developer